This month’s PGSQL Phriday #015 topic is about UUIDs, hosted by Lætitia Avrot. Lætitia has called for a debate. No, no, no. I say let’s have an all-out war. A benchmark war.
I have decided to orchestrate a benchmark war between four different methods of storing a primary key:
uuid data typebigint generated as identity data type.The challenge is simple: insert one million rows into a large table, while concurrently querying it, AS FAST AS YOU CAN!!!
Sadly I ran out of time. There’s one issue with my script, and I know how to fix it, but I need to get this blog published today or I won’t make the PGSQL Phriday cutoff!!
My problem is a bit amusing… the results successfully demonstrate how each option is better than the previous… until you get to bigint. I’ve demonstrated the size benefits of bigint but my uuidv7 performance is so good it basically matched bigint 😂 – but I’m guessing this is because my concurrent queries aren’t increasing cache pressure by using a uuid column yet… I suspect fixing this will demonstrate the performance gap between uuidv7 and bigint.
Regardless: there’s some good and useful stuff here – so let’s go ahead and dive in.
Test
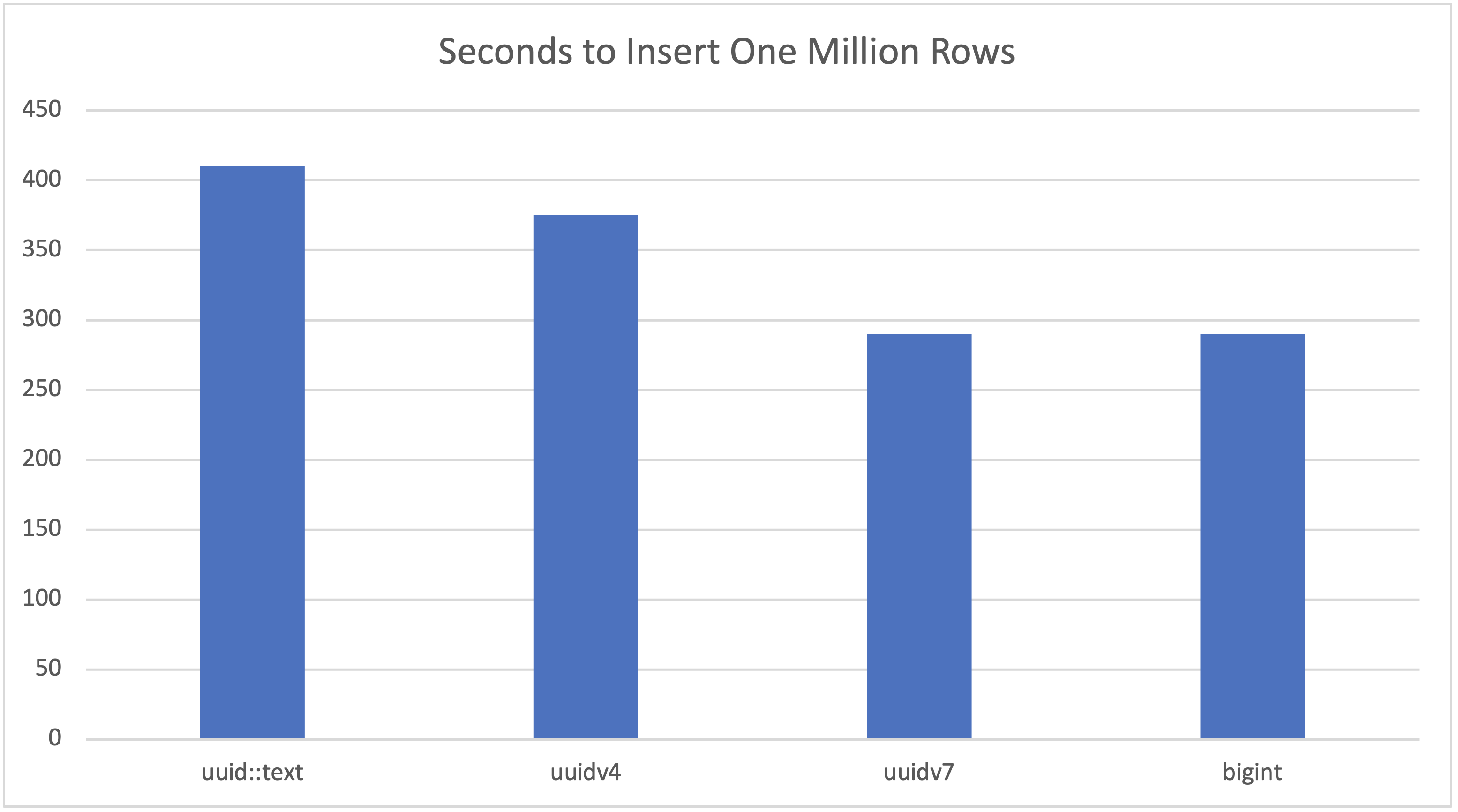
Time to Insert One Million Rows
Average Rate
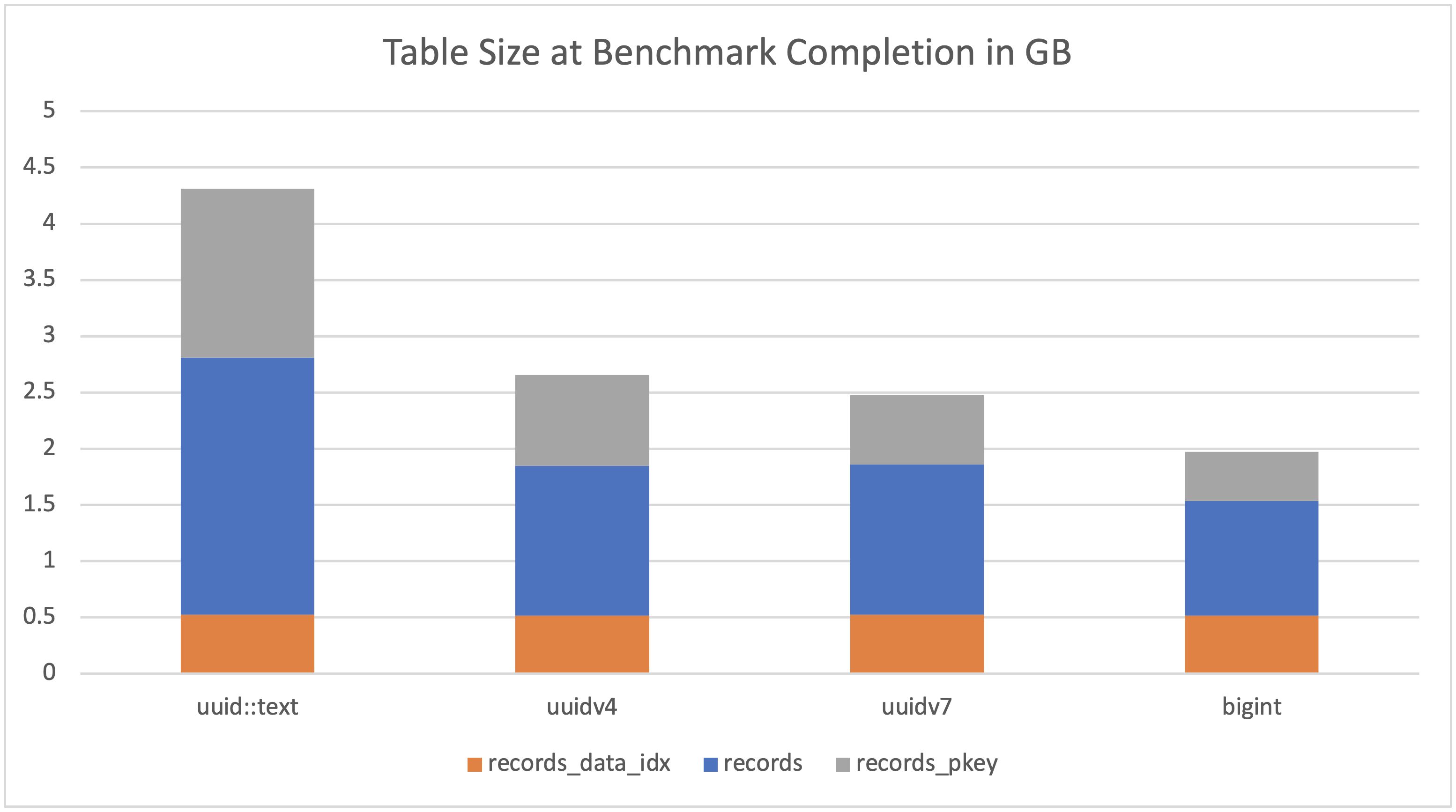
Size at Finish
Performance and Size Improvement
uuid::text
410 sec
2421 tps
4.31 gb
–
uuidv4
375 sec
2670 tps
2.65 gb
10% faster and
63% smaller than text
uuidv7
290 sec
3420 tps
2.47 gb
30% faster and
7% smaller than uuidv4
bigint
290 sec
3480 tps
1.97 gb
same speed (in this test) and
25% smaller than uuidv7
This benchmark is fully scripted and reproducible, based on my Copy-and-Paste Postgres Dev Env. Anyone can reproduce with a few simple copy-and-paste steps; the full details are at the bottom of this blog post.
Processor: 1 full core AMD EPYC Genoa, 3.7 GHz, 1 thread per core, 2GB memory (ec2 c7a.medium)
Storage: 16k IOPS, 1000 MB/s Throughput, 100 GB (ebs gp3)
Operating System: Ubuntu 22.04 LTS, Kernel 6.2.0-1017-aws #17~22.04.1-Ubuntu
PostgreSQL: main development branch as of Jan 29 2024 with v17 of the UUIDv7 patch
Settings: shared_buffers=1G / max_wal_size=204800
Schema: single table with 3 columns (id, foreign_table_id and data::bigint), data type for id and foreign_table_id follows the test
Initial Table Size: 20 million rows
Aside: The new c7a/m7a/r7a EC2 instance family is interesting because of the switch to core-per-vCPU, similar to graviton. While the top-end r7i.48xlarge (intel) has 96 physical cores with hyperthreading, the top-end r7a.48xlarge (amd) is a beast with 192 physical cores and 1.5TB of memory. I look forward to playing with PostgreSQL on one of these machines someday. 🏇
While my copy-and-paste-dev-env defaults to the free tier, I switched to a non-bursting instance family and added some beefy gp3 storage for this performance test.
The storage is significantly over-provisioned and could definitely be scaled down on all three dimensions to save quite a bit of money. I was in a hurry to make the publishing deadline and didn’t take the time to optimize this part.
It took a total of 4 hours and 13 minutes to run the benchmark 3 times in a row. The setup steps are copy-and-paste and take less than 10 minutes so lets round up to 4.5 hours. I also repeated the full test (three loops) on a second server to verify performance consistency. According to the official AWS pricing calculator at calculator.aws this is the cost breakdown:
GRAND TOTAL for both servers = US$ 2.02
Less than a cup of coffee.
Holy smokes batman – do we live in a different world than 20 years ago when it comes to the price of benchmarking or what?!! Also why is coffee so expensive?
Of course I had it running a bit longer while I was iterating and getting things ironed out, but I think the point stands. 🙂
Tests:
bigint generated by default as identity (cache 20)text default gen_random_uuid()uuid default gen_random_uuid()uuid default uuidv7() (current proposed syntax; may change before future release)Workload:
INIT_TABLE_ROWS=20000000PGBENCH_TRANSACTIONS_PER_CLIENT=100000PGBENCH_CLIENTS=10echo "\set search_data random(1,$INIT_TABLE_ROWS)insert into records(data) values(random()*$INIT_TABLE_ROWS);select * from records where data=:search_data;" >txn.sql
https://bxt.org/lpd65