
XML processing was all the rage 15 years ago; while it's lessprominent these days, it's still an important task in some application domains.In this post I'm going to compare the speed of stream-processing huge XML filesin Go, Python and C and finish up with a new, minimal module that uses C toaccelerate this task for Go. All the code shown throughout this post isavailable in this GitHub repository the newGo module is here.
First, let's define the problem at hand in more detail. Roughly speaking, thereare two ways we can process data from a file:
In many ways, (1) is more convenient because we can easily go back to any partof the file. However, in some situations (2) is essential; specifically, whenthe file is very large. This is where stream processing comes in. If our inputfile is 500 GiB, we're unlikely to be able to read it into memory and have toprocess it in parts. Even for smaller files that would theoretically fit intoRAM, it's not always a good idea to read them wholly; this dramaticallyincreases the active heap size and can cause performance issues ingarbage-collected languages.
For this benchmark, I'm using xmlgen tocreate a 230 MiB XML file . A tiny fragment of the file may look like this:
The task is to find how many times "Africa" appears in the data of the
Let's start with a baseline implementation - using the standard library'sencoding/xml package. While the package's Unmarshal mode will parse thewhole file in one go, it can also be used to process XML token by token andselectively parse interesting elements. Here is the code:
package mainimport ( "encoding/xml" "fmt" "io" "log" "os" "strings")type location struct { Data string `xml:",chardata"`}func main() { f, err := os.Open(os.Args[1]) if err != nil { log.Fatal(err) } defer f.Close() d := xml.NewDecoder(f) count := 0 for { tok, err := d.Token() if tok == nil || err == io.EOF { // EOF means we're done. break } else if err != nil { log.Fatalf("Error decoding token: %s", err) } switch ty := tok.(type) { case xml.StartElement: if ty.Name.Local == "location" { // If this is a start element named "location", parse this element // fully. var loc location if err = d.DecodeElement(&loc, &ty); err != nil { log.Fatalf("Error decoding item: %s", err) } if strings.Contains(loc.Data, "Africa") { count++ } } default: } } fmt.Println("count =", count)}
I made sure to double check that the memory usage of this program stays boundedand low while processing a large file - the maximum RSS was under 7 MiB whileprocessing our 230 MiB input file. I'm verifying this for all the programspresented in this post using /usr/bin/time -v on Linux.
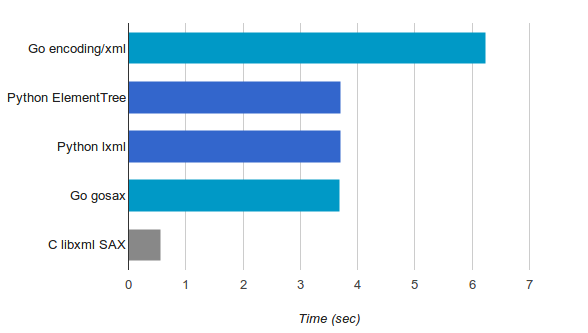
This program takes 6.24 seconds to process the whole file and print out theresult.
The first Python implementation uses the xml.etree.ElementTree module fromthe standard library:
import sysimport xml.etree.ElementTree as ETcount = 0for event, elem in ET.iterparse(sys.argv[1], events=("end",)): if event == "end": if elem.tag == 'location' and elem.text and 'Africa' in elem.text: count += 1 elem.clear()print('count =', count)
The key here is the elem.clear() call. It ensures that each element getsdiscarded afer parsing it fully, so the memory usage won't grow linearly withthe size of the file (unless the file is pathological). This program takes 3.7seconds to process the whole file - much faster than our Go program. Why isthat?
While the Go program uses 100% Go code for the task (encoding/xml isimplemented entirely in Go), the Python program is using a C extension (most ofElementTree is written in C) wrapping a fast XML parser in C - libexpat. The bulk of the work here is done inC, which is faster than Go.The performance of encoding/xml is further discussed inthis issue, though it's anold one and the performance has been somewhat optimized since then.
An alternative XML parsing library for Python is lxml,which uses libxml underneath. Here's a Pythonversion using lxml:
import sysfrom lxml import etreecount = 0for event, elem in etree.iterparse(sys.argv[1], events=("end",)): if event == "end": if elem.tag == 'location' and elem.text and 'Africa' in elem.text: count += 1 elem.clear()print('count =', count)
This looks very similar to the previous version, and that's on purpose. lxmlhas an etree-compatible API to make transition from the standard librarysmoother. This version also takes around 3.7 seconds for our 230 MiB file.
The reason I'm including lxml here is that it will run faster thanxml.etree.ElementTree when slurping the whole file, for our particular filesize. I want to highlight that this is outside of the scope for my experiment,because I only care about streaming processing. The only way (that I'm awareof!) to successfully process a 500 GiB file with lxml would be by usingiterparse.
Based on the measurements presented here, Go is about 68% slower than Python forparsing a large XML file in a streaming fashion. While Go usually compiles toa much faster code than pure Python, the Python implementations have the backingof efficient C libraries with which it's difficult to compete. I was curiousto know how fast it could be, in theory .
To answer this question, I implemented the same program using pure C withlibxml, which has a SAX API. I won't paste it whollyhere because it's longer, but you can find the full source code on GitHub.It takes just 0.56 seconds to process our 230 MiB input file, which is veryimpressive given the other results, but also not very surprising. This is C,after all.
You may wonder - if lxml uses libxml underneath, why is it so much slower thanthe pure C version? The answer is Python call overhead. The lxml version callsback into Python for every parsed element, which incurs a significantcost . Another reason is that my C implementation doesn't actually parse anelement - it's just a simple event-based state machine, so there's less extrawork being done.
To recap where we are so far:
We have two options: we can either try to optimize Go's encoding/xmlpackage, or we can try to wrap a fast C library with Go. While the former is aworthy goal, it involves a large effort and should be a topic for a separatepost. Here, I'll go for the latter.
Seaching around the web, I found a few wrappers around libxml. Two that seemedmoderately popular and maintained are https://github.com/lestrrat-go/libxml2and https://github.com/moovweb/gokogiri. Unfortunately, neither of these (orthe other bindings I found) are exposing the SAX API of libxml; instead, theyfocus on the DOM API, where the whole document is parsed by the underlyinglibrary and a tree is returned. As mentioned above, we need the SAX interfaceto process huge files.
It's time to roll our own :-) I wrote the gosax module, which uses Cgo to call into libxmland exposes a SAX interface . Implementing it was an interesting exercisein Cgo, because it requires some non-trivial concepts likeregistering Go callbacks with C.
Here's a version of our program using gosax:
package mainimport ( "fmt" "os" "strings" "github.com/eliben/gosax")func main() { counter := 0 inLocation := false scb := gosax.SaxCallbacks{ StartElement: func(name string, attrs []string) { if name == "location" { inLocation = true } else { inLocation = false } }, EndElement: func(name string) { inLocation = false }, Characters: func(contents string) { if inLocation && strings.Contains(contents, "Africa") { counter++ } }, } err := gosax.ParseFile(os.Args[1], scb) if err != nil { panic(err) } fmt.Println("counter =", counter)}
As you can see, it implements a state machine that remembers being insidea location element, where the character data is checked. This programtakes 4.03 seconds to process our input file. Not bad! But we can do a bitbetter, and with a couple of optimizationsI managed to bring it down to 3.68 seconds - about the same speed as the Pythonimplementations!
IMHO the roughly similar run times here are a coincidence, because the Pythonprograms are different from my approach in that they expose a higher-level APIthan pure SAX. Recall that iterparse returns a parsed element, and wecan access its text attribute, etc. In gosax, we have to do this much moremanually. Since the the cost of calls between Cgo and Go is rather high,there is an optimization opportunity here for gosax. We could do more work inC - parsing a full element, and returning it wholly to Go. This would move workfrom the Go side to the C side, as well as reduce the number of cross-languagecalls. But this is a task for another day.
Well, this was fun :-) There are 5 different implementations of the same simpletask described here, in 3 different programming languages. Here is a summaryof the speed measurements we got:
Python's performance story has always been - "it's probably fast enough, and inthe rare cases where it isn't, use a C extension". In Go the narrative issomewhat different: in most cases, the Go compiler produces fairly fast code.Pure Go code is significantly faster than Python and often faster than Java.Even so, every once in a while it may be useful to dip into C or C++ forperformance, and in these cases Cgo is a good approach.
It's obvious that encoding/xml needs some work w.r.t. performance, but until that happens - thereare good alternatives! Leveraging the speed of libxml has been possible for theDOM API, and now is possible for the SAX API as well. In the long run, I believethat serious performance work on encoding/xml can make it go faster thanthe libxml wrappers because it would elimitate the high cost of C-to-Go calls.
https://bxt.org/7z1kp